
I use npm run docs:check as a lightweight guardrail against documentation drift.
Under the hood it's one script: node scripts/check-docs.js. I wrote it after the third time I found a broken file reference in COMPONENTS.md while looking for something else. It wasn't dramatic — just a renamed component the docs still pointed to by its old name — but it annoyed me enough to fix.
This post covers the first-pass version of that script. I'll use this repo's implementation as the example instead of pretending at a generic version.
Why docs drift in the first place
It's usually not neglect, just mismatch. Renaming a file is one keypress in an IDE; updating every doc that references it is manual, easy to forget, and never urgent. Refactors move paths. APIs evolve. Docs stay frozen because nothing breaks immediately.
The pain surfaces later, often in the worst moments — when someone (usually future me) is trying to understand something quickly and follows a reference that no longer exists.
The approach in one sentence
Index the repo, extract file references from docs, validate those paths, verify a small set of symbol contracts1, and exit non-zero when anything drifts.
Building the script
What to check and why those choices
The script starts with an explicit scope:
const DOC_FILES = ['README.md', 'ARCHITECTURE.md', 'COMPONENTS.md', 'MAP.md'];
I deliberately kept this list short. My first instinct was to point it at every markdown file in the repo, but that created enormous false-positive noise from things like blog posts referencing files that don't live in this repo at all. Scoping it to the structural docs — the ones that are actually supposed to track the codebase — gave me the signal I wanted without the noise.
SYMBOL_CHECKS is the other half: a small list of high-value string markers in source files that should never disappear quietly. Things like a component's default export signature, or a required prop type. Not AST validation, just "if this exact string is gone, something changed and I should know."
Building a repo index
walkFiles() recursively builds allRepoFiles, skipping node_modules, .git, and public. That index is what makes basename lookups2 possible — so a doc can reference seo.jsx rather than the full path and still get validated.
I tried doing this lazily (only building the index if there were basename refs to resolve) but the logic got complicated fast and the full walk is cheap enough that it wasn't worth it.
Extracting and normalizing references
collectReferencedPaths(text) pulls references using two patterns:
CODE_SPAN_REfor inline code like`navigation.jsx`MD_LINK_REfor markdown links
Then each candidate goes through normalizeDocPath(), which is honestly where most of the real work happened. Getting this right took longer than I expected.
The normalization strips fragments, removes wrappers, and rejects obvious non-file references — URLs with ://, mailto: links, /memories/ paths (a special case from this site's content). Then it enforces a file-extension allowlist via FILE_EXT_RE.3
The rule I'm most glad I added: any path-like reference whose first segment isn't a known top-level directory in this repo gets discarded. This killed a whole class of false positives where docs would mention something like config/values in prose and the script would try to resolve it as a file path.
Resolving references
resolveReference(ref) handles two formats:
- path-like refs (contain
/): checked withfs.existsSync(path.join(repoRoot, rel)) - basename-only refs like
navigation.jsx: matched againstallRepoFiles
The basename rule is simple: one match passes, multiple matches also pass, zero matches fail. I went back and forth on that. Ambiguous references are a smell, but this repo has a few repeated names at different nesting levels, and failing those would have meant either renaming files or adding exceptions everywhere. I took the simpler option.
The two check passes
The docs pass reads each file in DOC_FILES, extracts and normalizes references, resolves them, and accumulates misses in missingPaths.
The symbol pass ensures the target file exists, reads the source, and checks each needle4 with code.includes(needle). Current contracts include things like:
export default Seo;insrc/components/seo.jsxslug: PropTypes.string.isRequiredinsrc/components/navigation-item.jsxexport default function useIsBrowser()insrc/hooks/useIsBrowser.jsx
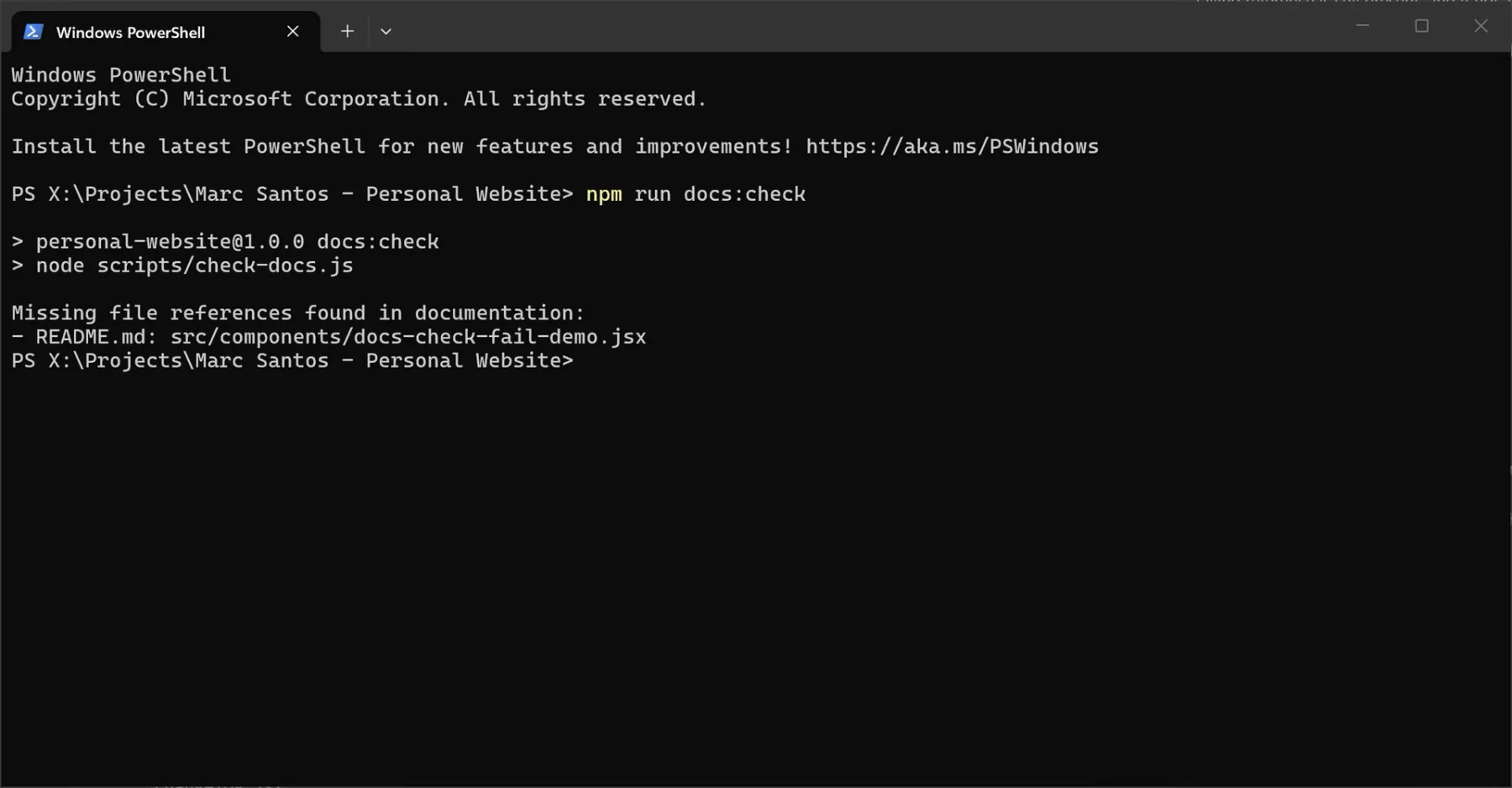
If both miss lists are empty, the script exits 0. Otherwise it prints what's missing and exits 1.5


Adapting this to your repo
If I were starting from scratch somewhere else, I'd start with the markdown link check and stop there for a while. It catches the common stuff — renamed files and moved paths — and the normalization logic stays simple. Symbol checks are worth adding once you have components or APIs you really don't want to change by accident, but they take more discipline to keep useful.
A few things worth deciding upfront: which docs are actually supposed to track the codebase (not all of them are), which file extensions count as valid references in your context, and whether basename matching makes sense for your directory structure. Those choices shape almost everything else.
Minimal starter you can copy
This covers the link-check case. Symbol contracts can be layered in once you're comfortable with what the baseline catches.
const fs = require('fs');
const path = require('path');
const repoRoot = path.resolve(__dirname, '..');
const DOC_FILES = ['README.md'];
const FILE_EXT_RE = /[A-Za-z0-9_./-]+\.(?:md|mdx|js|jsx|json|yml|yaml)$/;
const missing = [];
for (const doc of DOC_FILES) {
const docPath = path.join(repoRoot, doc);
if (!fs.existsSync(docPath)) continue;
const text = fs.readFileSync(docPath, 'utf8');
const refs = [...text.matchAll(/\[[^\]]+\]\(([^)]+)\)/g)].map((m) => m[1]);
refs.forEach((ref) => {
const normalized = ref.split('#')[0].replace(/^\.\//, '').replace(/^\//, '');
if (!FILE_EXT_RE.test(normalized)) return;
const exists = fs.existsSync(path.join(repoRoot, normalized));
if (!exists) missing.push(`${doc}: ${normalized}`);
});
}
if (missing.length === 0) {
console.log('Docs check passed: references are in sync.');
process.exit(0);
}
console.error('Missing file references found in documentation:');
missing.forEach((m) => console.error(`- ${m}`));
process.exit(1);
Wire it into npm scripts:
{
"scripts": {
"docs:check": "node scripts/check-docs.js"
}
}
And CI:
- name: Check docs drift
run: npm run docs:check
Expected output (these match the starter above, not the production script in this repo):
Pass:
Docs check passed: references are in sync.
Fail:
Missing file references found in documentation:
- README.md: src/components/old-file.jsx
What this doesn't catch
Because it's string-based, it won't catch AST-level semantic drift6, prose that has gone stale, or ambiguous basename references in repos where the same filename appears in many places. Those are real limits. But the goal here is speed and signal, and for that it's enough.
Most documentation breakage is just stale paths and vanished exports. Catching that before it ships is worth the script.
Footnotes
-
A symbol contract is a small, explicit code marker (string) that should remain present, used as a lightweight stability check. ↩
-
A basename is just the filename without its directory path (for example,
seo.jsxinstead ofsrc/components/seo.jsx). ↩ -
Normalization means cleaning and standardizing input so equivalent references can be compared consistently. ↩
-
In search examples, "needle" is a naming convention for the target term you are trying to find (from "needle in a haystack"). ↩
-
CI means continuous integration: automated checks that run in your pipeline before changes are merged or deployed. ↩
-
AST-level semantics refers to understanding code via its parsed syntax tree structure, not only via plain text matching. ↩




